揭秘GPU加速神器GTX980:性能实力何以超越CPU?
了解GPU加速
在深入分析GPU加速GTX980之前,我们先理解GPU加速的关键原理。GPU,即图像处理器,以同时处理大规模数据见长。它比CPU具备更丰富的并行处理单元。简言之,GPU加速原理在于利用GPU的协同运算特性,从而提高应用运行速率。因此,将部分任务转交给GPU处理,能有效地改善程序效能。
随着信息科技的快速发展,迫切需要新的数据处理方式以应对日益增长的数据和应用需求。相比于传统CPU的算力不足,GPU以其强大的并行计算优势走入人们的视野。而作为NVIDIA旗下性能卓越的显卡产品,GTX980所配备的GPU具备着极高的并行计算能力,非常适用于进行GPGPU加速运算。

GTX980显卡介绍
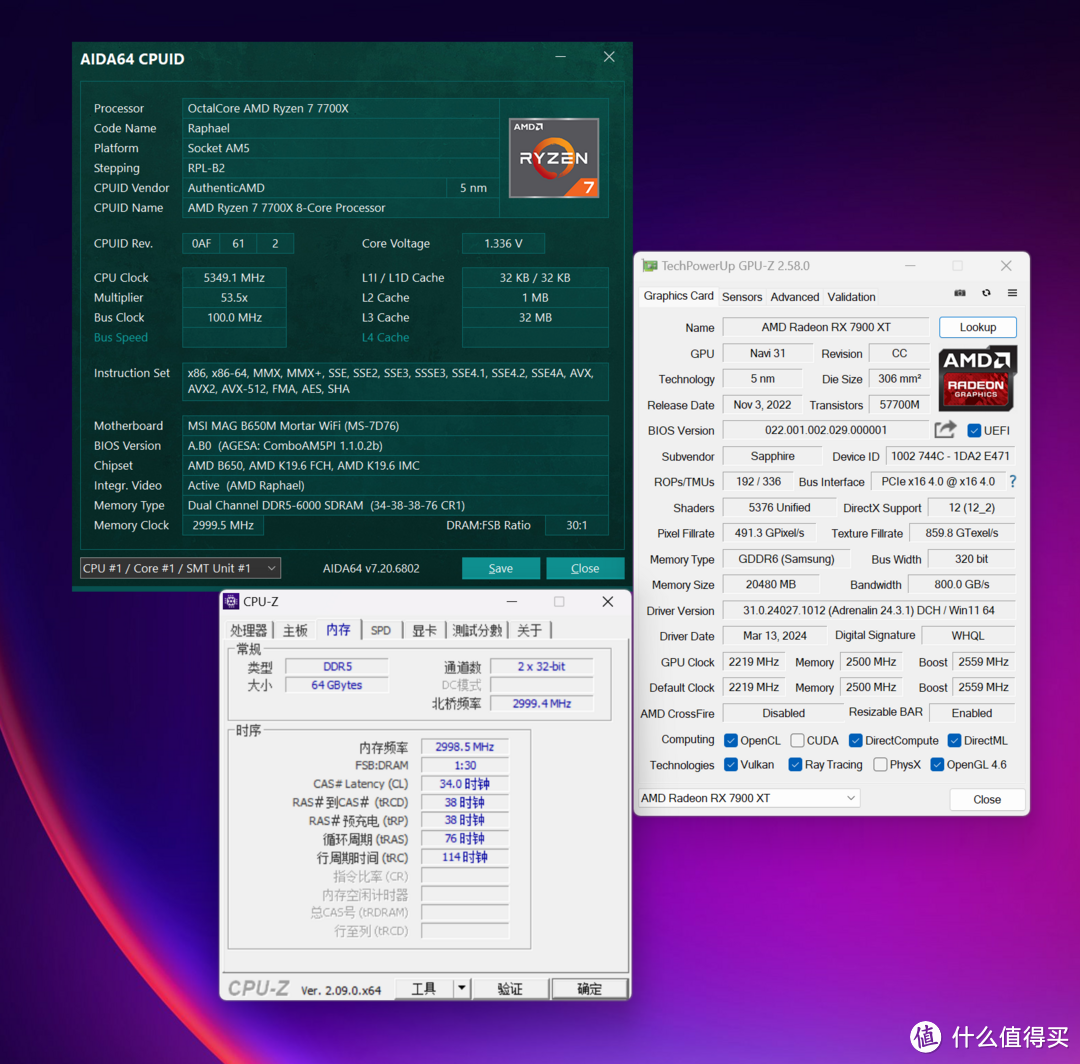
NVIDIA旗下的GTX 980,乃是Maxwell架构的杰出代表,搭载了高达2048个CUDA核心与4GB GDDR5显存,存储带宽达到256位,表现出强悍稳定的性能实力。作为当时的顶尖显卡之一,其卓越的表现不仅体现在游戏领域,同时在科学计算与AI等前沿领域亦有广泛应用。

精致卓越的 GTX980 显卡展现出强悍的运算和渲染实力,尤其在运用 GPU 提升运算效率方面卓尔不凡。出色的硬件架构与稳定性能使之成为深度学习以及图像处理等应用领域的上佳之选。
GPU加速应用领域

GPU加速技术,不仅限于某些行业领域,其广泛适用性使得它在众多行业均有涉猎。科学研究领域,比如气象模拟、地质勘探以及医学影像处理等对数据处理与复杂运算需求高的项目,可通过此技术提升工作效率。在人工智能及机器学习、深度学习等领域,同样离不开GPU加速技术作为核心推动力。
在各种研发及创新领域如工程设计、动画制以及虚拟现实等领域中,使用GPU加速能显著地减少渲染周期并提升工作效能,并能以高端品质完成任务。同样的,金融领域中对复杂数据的深度解读与高效的风险管理也受益于GPU加速技术。

如何实现GPU加速
为了发挥出GTX980的GPU加速性能,首当其冲的是确定具体任务的需求,从而选择恰当的软件工具与开发环境。现在市场上有许多这样的工具,例如CUDA、OpenCL、TensorFlow等等,它们都能够协助开发人员,有效挖掘GTX980的超强并行计算实力。

首先,在编制程序时,需把适合并发运算的部分交给GPU处理,同时通过调用相关API完成显卡间的沟通和数据传递。规划适当的并发运算流程且优化算法,对最大化利用GTX980 GPU的加速作用极其关键。
同时,硬件设计应注重稳定性与散热效率。须知,大量运算易致显卡过热,及时的散热措施能有效延缓硬件老化,保障系统稳定运转。

优势与挑战
采用搭载有强大的 NVIDIA GeForce GTX 980 GPU 的计算机可提供诸多卓越性能优势,例如提升作业效率、节约运营成本以及进一步稳固系统稳定性能等。得益于充分挖掘并合理运用显示卡硬件资源潜力,使得同样条件下能完成更多任务,并实现更快速地响应和满足用户迫切需求的目标。

然而,实际运作过程中,仍需应对一系列挑战。首当其冲的即为硬件兼容性问题,因技术差异与品牌众多导致显卡驱动问题频出或架构互相不兼容;其次,编程复杂程度较高,并发编程需充分考量数据同步及负载均衡等因素;最后也是关键的部分,即功耗与散热管理,长期处于高负荷状态须注意防止硬件过热损伤。
未来展望

在科技突破与壮大的背景下,GPU加速技术将拥有更深远的发展潜能。随着人工智能及深度学习需求量的增加,对高效能显卡以及相应的GPU加速技术水平的要求将日益攀升。
随着新兴技术如自动驾驶、虚拟现实及区块链的崛起,对高性能并行计算能力的需求日益强烈。凭借强大的性能表现,GTX980显卡未来的发展和应用潜力依然巨大。